8.0 KiB
Synonyms
Chinese Synonyms for Natural Language Processing and Understanding.
最好的中文近义词工具包。
synonyms可以用于自然语言理解的很多任务:文本对齐,推荐算法,相似度计算,语义偏移,关键字提取,概念提取,自动摘要,搜索引擎等。
Content:
- Install
- Usage
- Quick Get Start
- Valuation
- Benchmark
- Statement
- References
- Frequently Asked Questions
- License
Welcome
pip install -U synonyms
兼容py2和py3,当前稳定版本 v3.x。
Node.js 用户可以使用 node-synonyms了。
npm install node-synonyms

本文档的配置和接口说明面向python工具包, node版本查看项目。
Usage
支持使用环境变量配置分词词表和word2vec词向量文件。
| 环境变量 | 描述 |
|---|---|
| SYNONYMS_WORD2VEC_BIN_MODEL_ZH_CN | 使用word2vec训练的词向量文件,二进制格式。 |
| SYNONYMS_WORDSEG_DICT | 中文分词主字典,格式和使用参考 |
synonyms#nearby
import synonyms
print("人脸: %s" % (synonyms.nearby("人脸")))
print("识别: %s" % (synonyms.nearby("识别")))
print("NOT_EXIST: %s" % (synonyms.nearby("NOT_EXIST")))
synonyms.nearby(WORD)返回一个元组,元组中包含两项:([nearby_words], [nearby_words_score]),nearby_words是WORD的近义词们,也以list的方式存储,并且按照距离的长度由近及远排列,nearby_words_score是nearby_words中对应位置的词的距离的分数,分数在(0-1)区间内,越接近于1,代表越相近。比如:
synonyms.nearby(人脸) = (
["图片", "图像", "通过观察", "数字图像", "几何图形", "脸部", "图象", "放大镜", "面孔", "Mii"],
[0.597284, 0.580373, 0.568486, 0.535674, 0.531835, 0.530
095, 0.525344, 0.524009, 0.523101, 0.516046])
在OOV的情况下,返回 ([], []),目前的字典大小: 125,792。
synonyms#compare
两个句子的相似度比较
sen1 = "发生历史性变革"
sen2 = "发生历史性变革"
r = synonyms.compare(sen1, sen2, seg=True)
其中,参数 seg 表示 synonyms.compare是否对sen1 和 sen2进行分词,默认为 True。返回值:[0-1],并且越接近于1代表两个句子越相似。
旗帜引领方向 vs 道路决定命运: 0.429
旗帜引领方向 vs 旗帜指引道路: 0.93
发生历史性变革 vs 发生历史性变革: 1.0
synonyms#display
以友好的方式打印近义词,方便调试,display调用了 synonyms#nearby 方法。
>>> synonyms.display("飞机")
'飞机'近义词:
1. 架飞机:0.837399
2. 客机:0.764609
3. 直升机:0.762116
4. 民航机:0.750519
5. 航机:0.750116
6. 起飞:0.735736
7. 战机:0.734975
8. 飞行中:0.732649
9. 航空器:0.723945
10. 运输机:0.720578
PCA

Samples

Quick Get Start
$ pip install -r Requirements.txt
$ python demo.py
Voice of Users

Data
synonyms/data/words.nearby.x.pklz # compressed pickle object
data is built based on wikidata-corpus.
Valuation
同义词词林
《同义词词林》是梅家驹等人于1983年编纂而成,现在使用广泛的是哈工大社会计算与信息检索研究中心维护的《同义词词林扩展版》,它精细的将中文词汇划分成大类和小类,梳理了词汇间的关系,同义词词林扩展版包含词语7万余条,其中3万余条被以开放数据形式共享。
知网, HowNet
HowNet,也被称为知网,它并不只是一个语义字典,而是一个知识系统,词汇之间的关系是其一个基本使用场景。知网包含词语8余条。
国际上对词语相似度算法的评价标准普遍采用 Miller&Charles 发布的英语词对集的人工判定值。该词对集由十对高度相关、十对中度相关、十对低度相关共 30 个英语词对组成,然后让38个受试者对这30对进行语义相关度判断,最后取他们的平均值作为人工判定标准。然后不同近义词工具也对这些词汇进行相似度评分,与人工判定标准做比较,比如使用皮尔森相关系数。在中文领域,使用这个词表的翻译版进行中文近义词比较也是常用的办法。
对比
Synonyms的词表容量是125,792,下面选择一些在同义词词林、知网和Synonyms都存在的几个词,给出其近似度的对比:
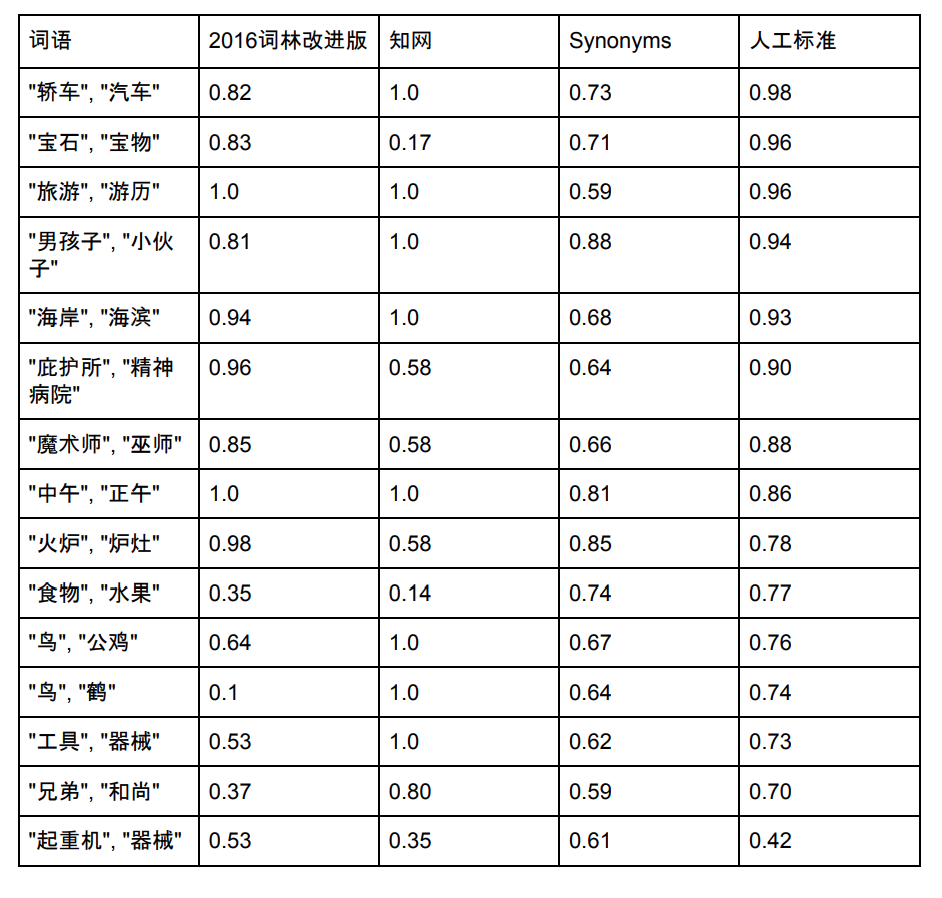
注:同义词林及知网数据、分数来源。Synonyms也在不断优化中,新的分数可能和上图不一致。
Benchmark
Test with py3, MacBook Pro.
python benchmark.py
++++++++++ OS Name and version ++++++++++
Platform: Darwin
Kernel: 16.7.0
Architecture: ('64bit', '')
++++++++++ CPU Cores ++++++++++
Cores: 4
CPU Load: 60
++++++++++ System Memory ++++++++++
meminfo 8GB
synonyms#nearby: 100000 loops, best of 3 epochs: 0.209 usec per loop
Live Sharing
线上分享实录: Synonyms 中文近义词工具包 @ 2018-02-07
Statement
Synonyms发布证书 GPL 3.0。数据和程序可用于研究和商业产品,必须注明引用和地址,比如发布的任何媒体、期刊、杂志或博客等内容。
@online{Synonyms:hain2017,
author = {Hai Liang Wang, Hu Ying Xi},
title = {中文近义词工具包Synonyms},
year = 2017,
url = {https://github.com/huyingxi/Synonyms},
urldate = {2017-09-27}
}
任何基于Synonyms衍生的数据和项目也需要开放并需要声明一致的“声明”。
References
Frequently Asked Questions (FAQ)
- 是否支持添加单词到词表中?
不支持,欲了解更多请看 #5
- 词向量的训练是用哪个工具?
Google发布的word2vec,该库由C语言编写,内存使用效率高,训练速度快。gensim可以加载word2vec输出的模型文件。