3.9 KiB
#Introduction
This program is a realization of TwitterRank Algorithm.This algorithm aims to find the most influential user on different topics in Twitter and other similar social network service.First it use LDA to find some topics,then this algorithm will calculate the rank of users in this topic based on his influence on his followers and his interest about this topic.
#How to get Data
First we need to pick some users.The dataset doesn't need to be very big but users in this database should have close relationship,because in this case we can ensure most of users have influence on others.So I pick top 100 twitter users based on the number of their followers.Because many of them follow other top 100 twitter users.It's easy to get their user id from twitaholic.com,I wrote a script to get their user id.The code is in GetTopTwitters.py.
TwitterRank Algorithm needs users' tweets' content,the number of their tweets,and their relationship to get the rank,so I wrote a spider to get them.The code is in spider.py,I use the Tweepy library to use Twitter API easier.
#Detail of TwitterRank
Each user's tweets is a sample,first I process their tweets.I delete punctuation and words in stop words list.Stop words list is in the file StopWords.py.Then we need to find all words appeared in these samples,and for each sample I get a list,the i-th column is the number of times i-th word appeared in this sample.Then I use LDA process the data and get the DT,it's a matrix,i rows and j columns,i is the number of samples and j is the number of topics,the value of DT-ij means i-th sample's interested in topic j.The purpose is to find the list of TR-t for each topic.The i-th element in TR-t is the influence of i-th sample in topic t.According to the paper,we need to find Pt and Et to get TR-t.Here is some formulas:



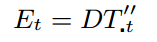
Please read the paper to get the meaning of each parameter.Pt is a matrix,i rows and i columns,i is the number of samples.Pt-ij is the influence from j to i in topic t.I can use the number of users' tweets, their relationship and matrix DT to get Pt,and we can get Et from DT too.The formula to get TR-t is an iteration.This formula is some thing like PageRank,it get TR-t based on this user's influence on his followers and his followers' influence on this topic.Second part of this formula is Et,which reflect users' interest on this topic.γ is a parameter between 0 and 1,a bigger γ means Pt is more important,and vice versa.
#Result
Here is the result,we set 5 topics and the γ is 0.5:
- Topic 1: amp today time love
- Most influential user:coldplay
- Topic 2: shamitabh claudialeitte mais muito
- Most influential user:10Ronaldinho
- Topic 3: posted president obama photo
- Most influential user:cnnbrk
- Topic 4: love christmas happy amp
- Most influential user:NICKIMINAJ
- Topic 5: para del twitter con
- Most influential user:twitter_es
#Issues
Although result seems not so bad but we still find some issues.First the sim value is not so useful.sim is supposed to measure similarity between two users in this topic,but most of times it's value is bigger than 0.8,this means if user A follows user B,and user B is interested in topic T,but user A is not interested in it,user B still has a big influence on user A in topic T.What's more,if neither of user A and user B is interested in topic T,the value of sim will be bigger.Obviously it's not reasonable.
And if user A follows a lot of people,each of his friend will have little influence on him.This completion assume each user spend same time on Twitter every day.But the fact is that the user who follows more people will spend more time on Twitter.Based on these,we think TwitterRank Algorithm can still be improved.