Pytorch code for our AAAI 2020 paper "Path Ranking with Attention to Type Hierarchies"
Bumps [protobuf](https://github.com/protocolbuffers/protobuf) from 3.7.1 to 3.18.3. - [Release notes](https://github.com/protocolbuffers/protobuf/releases) - [Changelog](https://github.com/protocolbuffers/protobuf/blob/main/generate_changelog.py) - [Commits](https://github.com/protocolbuffers/protobuf/compare/v3.7.1...v3.18.3) --- updated-dependencies: - dependency-name: protobuf dependency-type: direct:production ... Signed-off-by: dependabot[bot] <support@github.com> |
||
|---|---|---|
| docs | ||
| figure | ||
| main | ||
| pra_templates | ||
| .gitignore | ||
| demo_fb15k237.py | ||
| demo_wn18rr.py | ||
| LICENSE | ||
| README.md | ||
| requirements.txt | ||
| run_fb15k237.py | ||
| run_wn18rr.py | ||
| run.py | ||
Path Ranking with Attention to Type Hierarchies
This repo contains code for AAAI 2020 paper Path Ranking with Attention to Type Hierarchies, in which we introduce Attentive Path Ranking (APR), a novel path pattern representation that leverages type hierarchies of entities to both avoid ambiguity and maintain generalization.
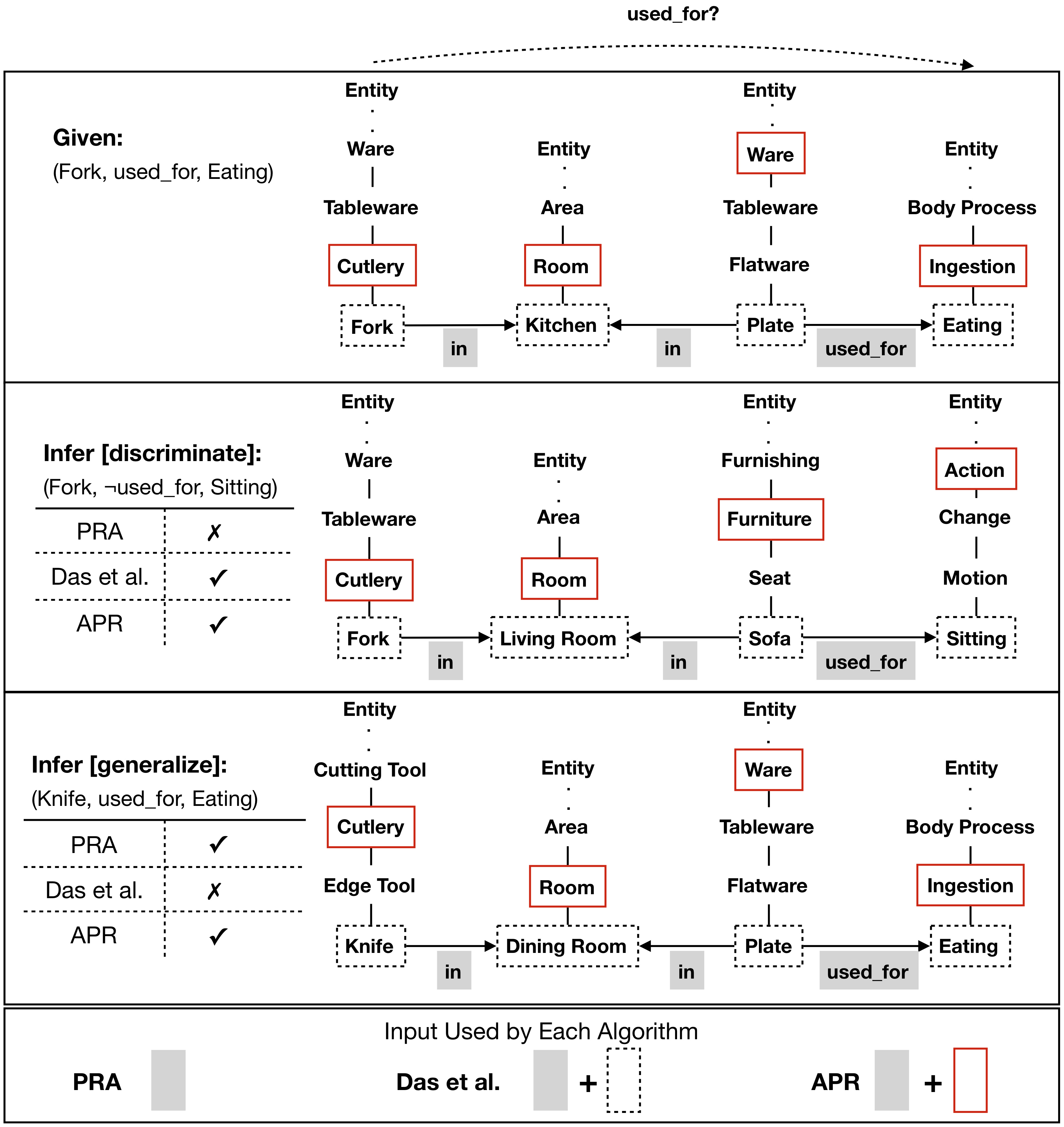
Resources
- Code for baseline models in the paper can be found here (PRA and SFE) and here (Path-RNN).
- We provide tokenized data for WN18RR and FB15k-237. Our data format follows ChainsofReasoning. Vocabularies used for tokenizing data are also provided for reference.
- Raw data for WN18RR and FB15k-237 can be found here. Types for WN18RR entities can be obtained from Wordnet. Types for FB15k-237 entities can be found here.
Tested platform
- Hardware: 64GB RAM, 12GB GPU memory
- Software: ubuntu 16.04, python 3.5, cuda 8
Setup
- Install cuda
- (Optional) Set up python virtual environment by running
virtualenv -p python3 . - (Optional) Activate virtual environment by running
source bin/activate - Install pytorch with cuda
- Install requirements by running
pip3 install -r requirements.txt
Quick Start for Attentive Path Ranking (APR) model
To help you quickly train and test the model, we have prepared data that are already vectorized.
Data
- Vectorized data file can be downloaded from dropbox.
- Unzip the file in the root directory of this repo.
Run the model
- Use
run.pyto train and test the model on WN18RR or FB15k-237. - Use
main/playground/model2/CompositionalVectorSpaceAlgorithm.pyto modify the training settings and hyperparamters. - Use
main/playground/model2/CompositionalVectorSpaceModel.pyto modify the network design. Different attention methods for types and paths can be selected here. - Training progress can be monitored using tensorboardX by running
tensorboard --logdir runs. Tutorials and Details can be found here.
Running the Complete Knowledge Graph Completion Pipeline
You can also use the code to build knowledge graphs from relation data, sample negative examples, create splits, extract paths, vectorize path data, run baselines, and run APR model.
Data
- Raw data, including relation data, type information, and word embeddings, for WN18RR, FB15k-237 can be downloaded from dropbox.
- Unzip the file in the root directory of this repo.
Install Dependencies
- Clone our PRA repo and install necessary dependencies. For more details, check out readme in that repo.
- (Optional) Clone our CVSM repo only if you want to run CVSM baselines.
Run
- Use
demo_wn18rr.pyordemo_fb15k237.pyto go through the whole pipeline for the respective dataset. - Use
run_wn18rr.pyorrun_fb15k237.pyif you want to run PRA, SFE, and CVSM baselines
Code Documentation
Code are documented with docstrings. We also use sphinx to automatically generate API documentation from docstrings.
Viewing the documentation
- Make sure you have the necessary
pipdependencies ofsphinxinstalled. - Navigate to
docsand build the documentation:make html - Navigate to
docs/_build/html(this folder will be generated by the previous command) and start a simple server:python -m SimpleHTTPServer. - Navigate to
http://localhost:8000in your browser.
Citation
Please cite the following work if you find the data/code useful.
@inproceedings{liu2019path,
title = {Path Ranking with Attention to Type Hierarchies},
author = {Weiyu Liu and Daruna, Angel and Kira, Zsolt and Chernova, Sonia},
booktitle = {Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI)},
year = {2020}
}