Differentiable Neural Computers, Sparse Access Memory and Sparse Differentiable Neural Computers, for Pytorch
| dnc | ||
| docs | ||
| tasks | ||
| test | ||
| .gitignore | ||
| .travis.yml | ||
| LICENSE | ||
| README.md | ||
| release.sh | ||
| setup.cfg | ||
| setup.py | ||
Differentiable Neural Computer, for Pytorch

![]()
This is an implementation of Differentiable Neural Computers, described in the paper Hybrid computing using a neural network with dynamic external memory, Graves et al.
Install
pip install dnc
Architecure

Usage
Parameters:
| Argument | Default | Description |
|---|---|---|
| input_size | None | Size of the input vectors |
| hidden_size | None | Size of hidden units |
| rnn_type | 'lstm' | Type of recurrent cells used in the controller |
| num_layers | 1 | Number of layers of recurrent units in the controller |
| num_hidden_layers | 2 | Number of hidden layers per layer of the controller |
| bias | True | Bias |
| batch_first | True | Whether data is fed batch first |
| dropout | 0 | Dropout between layers in the controller |
| bidirectional | False | If the controller is bidirectional (Not yet implemented) |
| nr_cells | 5 | Number of memory cells |
| read_heads | 2 | Number of read heads |
| cell_size | 10 | Size of each memory cell |
| nonlinearity | 'tanh' | If using 'rnn' as rnn_type, non-linearity of the RNNs |
| gpu_id | -1 | ID of the GPU, -1 for CPU |
| independent_linears | False | Whether to use independent linear units to derive interface vector |
| share_memory | True | Whether to share memory between controller layers |
| reset_experience | False | Whether to reset memory (This is a parameter for the forward pass) |
Example usage:
from dnc import DNC
rnn = DNC(
input_size=64,
hidden_size=128,
rnn_type='lstm',
num_layers=4,
nr_cells=100,
cell_size=32,
read_heads=4,
batch_first=True,
gpu_id=0
)
(controller_hidden, memory, read_vectors) = (None, None, None)
output, (controller_hidden, memory, read_vectors) = \
rnn(torch.randn(10, 4, 64), (controller_hidden, memory, read_vectors, reset_experience=True))
Example copy task
The copy task, as descibed in the original paper, is included in the repo.
From the project root:
python ./tasks/copy_task.py -cuda 0
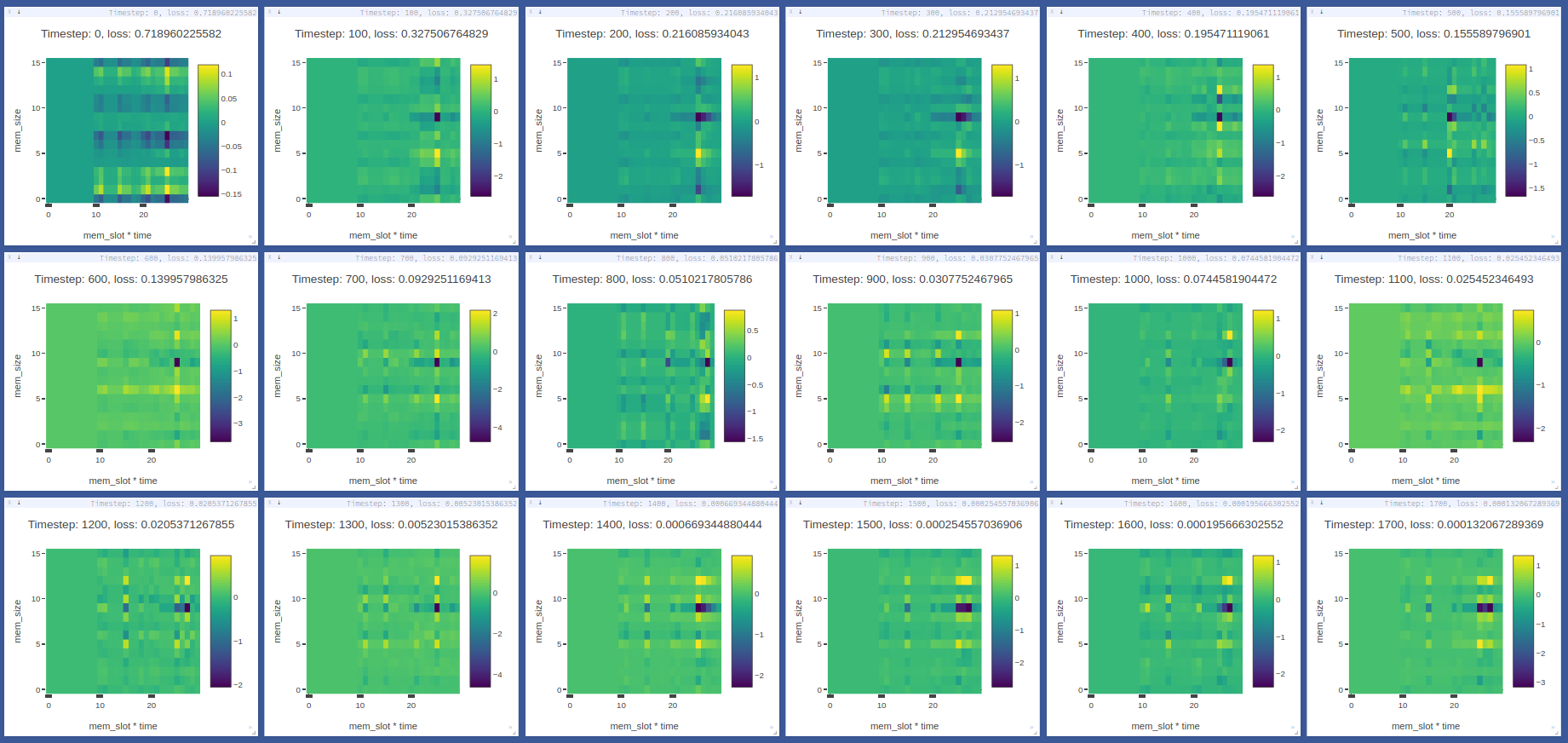
The copy task can be used to debug memory using Visdom.
Additional step required:
pip install visdom
python -m visdom.server
Open http://localhost:8097/ on your browser, and execute the copy task:
python ./tasks/copy_task.py -cuda 0
The visdom dashboard shows memory as a heatmap for batch 0 every -summarize_freq iteration:
General noteworthy stuff
- DNCs converge with Adam and RMSProp learning rules, SGD generally causes them to diverge.
Repos referred to for creation of this repo: