| dnc | ||
| docs | ||
| tasks | ||
| test | ||
| .gitignore | ||
| .travis.yml | ||
| LICENSE | ||
| README.md | ||
| release.sh | ||
| setup.cfg | ||
| setup.py | ||
Differentiable Neural Computer, for Pytorch

![]()
This is an implementation of Differentiable Neural Computers, described in the paper Hybrid computing using a neural network with dynamic external memory, Graves et al.
Install
pip install dnc
Architecure

Usage
Parameters:
Following are the constructor parameters:
| Argument | Default | Description |
|---|---|---|
| input_size | None |
Size of the input vectors |
| hidden_size | None |
Size of hidden units |
| rnn_type | 'lstm' |
Type of recurrent cells used in the controller |
| num_layers | 1 |
Number of layers of recurrent units in the controller |
| num_hidden_layers | 2 |
Number of hidden layers per layer of the controller |
| bias | True |
Bias |
| batch_first | True |
Whether data is fed batch first |
| dropout | 0 |
Dropout between layers in the controller |
| bidirectional | False |
If the controller is bidirectional (Not yet implemented |
| nr_cells | 5 |
Number of memory cells |
| read_heads | 2 |
Number of read heads |
| cell_size | 10 |
Size of each memory cell |
| nonlinearity | 'tanh' |
If using 'rnn' as rnn_type, non-linearity of the RNNs |
| gpu_id | -1 |
ID of the GPU, -1 for CPU |
| independent_linears | False |
Whether to use independent linear units to derive interface vector |
| share_memory | True |
Whether to share memory between controller layers |
Following are the forward pass parameters:
| Argument | Default | Description |
|---|---|---|
| input | - | The input vector (B*T*X) or (T*B*X) |
| hidden | (None,None,None) |
Hidden states (controller hidden, memory hidden, read vectors) |
| reset_experience | False |
Whether to reset memory (This is a parameter for the forward pass |
| pass_through_memory | True |
Whether to pass through memory (This is a parameter for the forward pass |
Example usage:
from dnc import DNC
rnn = DNC(
input_size=64,
hidden_size=128,
rnn_type='lstm',
num_layers=4,
nr_cells=100,
cell_size=32,
read_heads=4,
batch_first=True,
gpu_id=0
)
(controller_hidden, memory, read_vectors) = (None, None, None)
output, (controller_hidden, memory, read_vectors) = \
rnn(torch.randn(10, 4, 64), (controller_hidden, memory, read_vectors, reset_experience=True))
Debugging:
The debug option causes the network to return its memory hidden vectors (numpy ndarrays) for the first batch each forward step.
These vectors can be analyzed or visualized, using visdom for example.
from dnc import DNC
rnn = DNC(
input_size=64,
hidden_size=128,
rnn_type='lstm',
num_layers=4,
nr_cells=100,
cell_size=32,
read_heads=4,
batch_first=True,
gpu_id=0,
debug=True
)
(controller_hidden, memory, read_vectors) = (None, None, None)
output, (controller_hidden, memory, read_vectors), debug_memory = \
rnn(torch.randn(10, 4, 64), (controller_hidden, memory, read_vectors, reset_experience=True))
Memory vectors returned by forward pass (np.ndarray):
| Key | Y axis (dimensions) | X axis (dimensions) |
|---|---|---|
debug_memory['memory'] |
layer * time | nr_cells * cell_size |
debug_memory['link_matrix'] |
layer * time | nr_cells * nr_cells |
debug_memory['precedence'] |
layer * time | nr_cells |
debug_memory['read_weights'] |
layer * time | read_heads * nr_cells |
debug_memory['write_weights'] |
layer * time | nr_cells |
debug_memory['usage_vector'] |
layer * time | nr_cells |
Example copy task
The copy task, as descibed in the original paper, is included in the repo.
From the project root:
python ./tasks/copy_task.py -cuda 0 -optim rmsprop -batch_size 32 -mem_slot 64 # (like original implementation)
python3 ./tasks/copy_task.py -cuda 0 -lr 0.001 -rnn_type lstm -nlayer 1 -nhlayer 2 -dropout 0 -mem_slot 32 -batch_size 1000 -optim adam -sequence_max_length 8 # (faster convergence)
For the full set of options, see:
python ./tasks/copy_task.py --help
The copy task can be used to debug memory using Visdom.
Additional step required:
pip install visdom
python -m visdom.server
Open http://localhost:8097/ on your browser, and execute the copy task:
python ./tasks/copy_task.py -cuda 0
The visdom dashboard shows memory as a heatmap for batch 0 every -summarize_freq iteration:
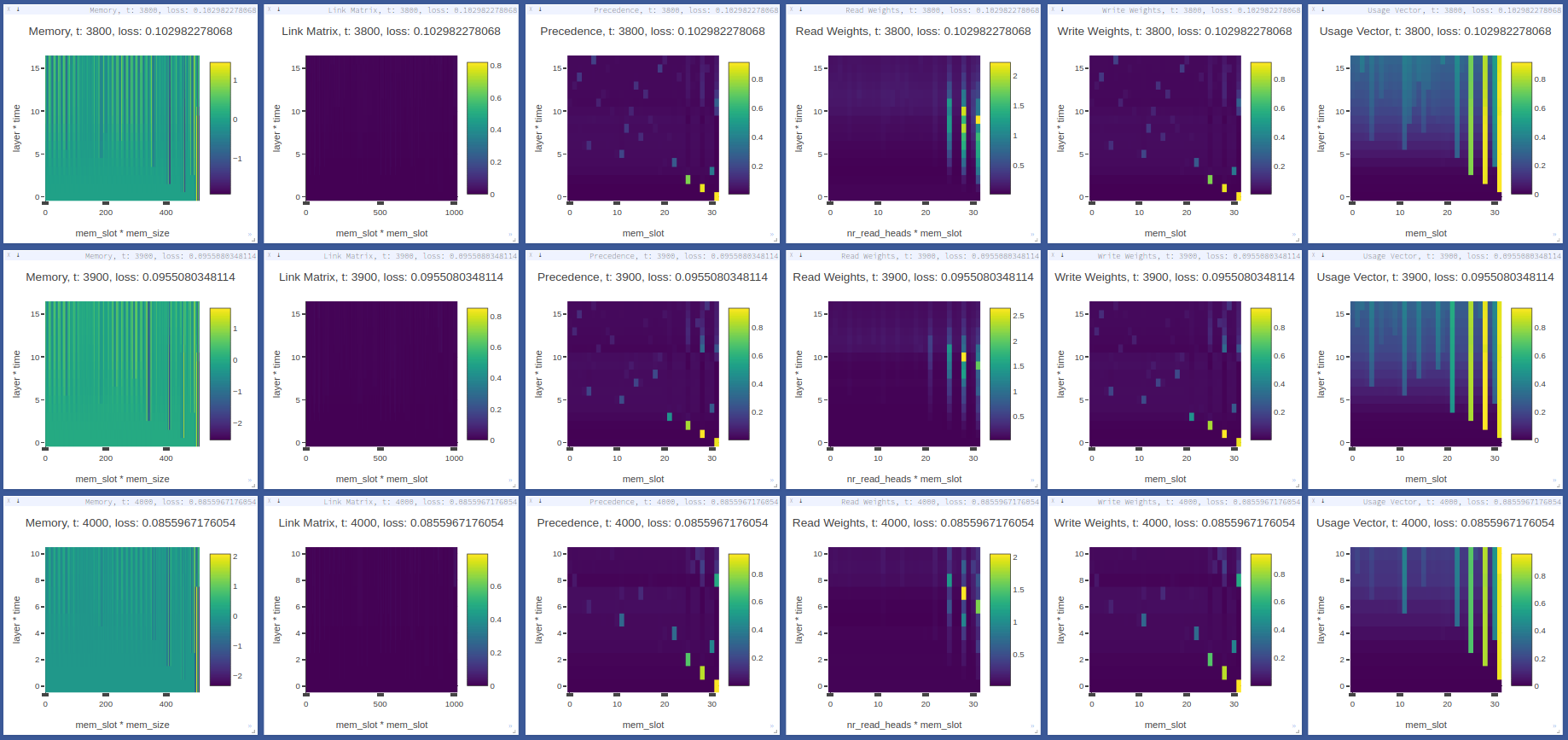
General noteworthy stuff
- DNCs converge with Adam and RMSProp learning rules, SGD generally causes them to diverge.
Repos referred to for creation of this repo: