commit
7f4a8e892d
96
README.md
96
README.md
@ -18,28 +18,38 @@ pip install dnc
|
||||
|
||||
**Parameters**:
|
||||
|
||||
Following are the constructor parameters:
|
||||
|
||||
| Argument | Default | Description |
|
||||
| --- | --- | --- |
|
||||
| input_size | None | Size of the input vectors |
|
||||
| hidden_size | None | Size of hidden units |
|
||||
| rnn_type | 'lstm' | Type of recurrent cells used in the controller |
|
||||
| num_layers | 1 | Number of layers of recurrent units in the controller |
|
||||
| num_hidden_layers | 2 | Number of hidden layers per layer of the controller |
|
||||
| bias | True | Bias |
|
||||
| batch_first | True | Whether data is fed batch first |
|
||||
| dropout | 0 | Dropout between layers in the controller |
|
||||
| bidirectional | False | If the controller is bidirectional (Not yet implemented) |
|
||||
| nr_cells | 5 | Number of memory cells |
|
||||
| read_heads | 2 | Number of read heads |
|
||||
| cell_size | 10 | Size of each memory cell |
|
||||
| nonlinearity | 'tanh' | If using 'rnn' as `rnn_type`, non-linearity of the RNNs |
|
||||
| gpu_id | -1 | ID of the GPU, -1 for CPU |
|
||||
| independent_linears | False | Whether to use independent linear units to derive interface vector |
|
||||
| share_memory | True | Whether to share memory between controller layers |
|
||||
| reset_experience | False | Whether to reset memory (This is a parameter for the forward pass) |
|
||||
| input_size | `None` | Size of the input vectors |
|
||||
| hidden_size | `None` | Size of hidden units |
|
||||
| rnn_type | `'lstm'` | Type of recurrent cells used in the controller |
|
||||
| num_layers | `1` | Number of layers of recurrent units in the controller |
|
||||
| num_hidden_layers | `2` | Number of hidden layers per layer of the controller |
|
||||
| bias | `True` | Bias |
|
||||
| batch_first | `True` | Whether data is fed batch first |
|
||||
| dropout | `0` | Dropout between layers in the controller |
|
||||
| bidirectional | `False` | If the controller is bidirectional (Not yet implemented |
|
||||
| nr_cells | `5` | Number of memory cells |
|
||||
| read_heads | `2` | Number of read heads |
|
||||
| cell_size | `10` | Size of each memory cell |
|
||||
| nonlinearity | `'tanh'` | If using 'rnn' as `rnn_type`, non-linearity of the RNNs |
|
||||
| gpu_id | `-1` | ID of the GPU, -1 for CPU |
|
||||
| independent_linears | `False` | Whether to use independent linear units to derive interface vector |
|
||||
| share_memory | `True` | Whether to share memory between controller layers |
|
||||
|
||||
Following are the forward pass parameters:
|
||||
|
||||
| Argument | Default | Description |
|
||||
| --- | --- | --- |
|
||||
| input | - | The input vector `(B*T*X)` or `(T*B*X)` |
|
||||
| hidden | `(None,None,None)` | Hidden states `(controller hidden, memory hidden, read vectors)` |
|
||||
| reset_experience | `False` | Whether to reset memory (This is a parameter for the forward pass |
|
||||
| pass_through_memory | `True` | Whether to pass through memory (This is a parameter for the forward pass |
|
||||
|
||||
|
||||
Example usage:
|
||||
### Example usage:
|
||||
|
||||
```python
|
||||
from dnc import DNC
|
||||
@ -62,13 +72,58 @@ output, (controller_hidden, memory, read_vectors) = \
|
||||
rnn(torch.randn(10, 4, 64), (controller_hidden, memory, read_vectors, reset_experience=True))
|
||||
```
|
||||
|
||||
### Debugging:
|
||||
|
||||
The `debug` option causes the network to return its memory hidden vectors (numpy `ndarray`s) for the first batch each forward step.
|
||||
These vectors can be analyzed or visualized, using visdom for example.
|
||||
|
||||
```python
|
||||
from dnc import DNC
|
||||
|
||||
rnn = DNC(
|
||||
input_size=64,
|
||||
hidden_size=128,
|
||||
rnn_type='lstm',
|
||||
num_layers=4,
|
||||
nr_cells=100,
|
||||
cell_size=32,
|
||||
read_heads=4,
|
||||
batch_first=True,
|
||||
gpu_id=0,
|
||||
debug=True
|
||||
)
|
||||
|
||||
(controller_hidden, memory, read_vectors) = (None, None, None)
|
||||
|
||||
output, (controller_hidden, memory, read_vectors), debug_memory = \
|
||||
rnn(torch.randn(10, 4, 64), (controller_hidden, memory, read_vectors, reset_experience=True))
|
||||
```
|
||||
|
||||
Memory vectors returned by forward pass (`np.ndarray`):
|
||||
|
||||
| Key | Y axis (dimensions) | X axis (dimensions) |
|
||||
| --- | --- | --- |
|
||||
| `debug_memory['memory']` | layer * time | nr_cells * cell_size
|
||||
| `debug_memory['link_matrix']` | layer * time | nr_cells * nr_cells
|
||||
| `debug_memory['precedence']` | layer * time | nr_cells
|
||||
| `debug_memory['read_weights']` | layer * time | read_heads * nr_cells
|
||||
| `debug_memory['write_weights']` | layer * time | nr_cells
|
||||
| `debug_memory['usage_vector']` | layer * time | nr_cells
|
||||
|
||||
## Example copy task
|
||||
|
||||
The copy task, as descibed in the original paper, is included in the repo.
|
||||
|
||||
From the project root:
|
||||
```bash
|
||||
python ./tasks/copy_task.py -cuda 0
|
||||
python ./tasks/copy_task.py -cuda 0 -optim rmsprop -batch_size 32 -mem_slot 64 # (original implementation)
|
||||
|
||||
python ./tasks/copy_task.py -cuda 0 -lr 0.001 -rnn_type lstm -nlayer 1 -nhlayer 2 -mem_slot 32 -batch_size 32 -optim adam # (faster convergence)
|
||||
```
|
||||
|
||||
For the full set of options, see:
|
||||
```
|
||||
python ./tasks/copy_task.py --help
|
||||
```
|
||||
|
||||
The copy task can be used to debug memory using [Visdom](https://github.com/facebookresearch/visdom).
|
||||
@ -88,13 +143,12 @@ python ./tasks/copy_task.py -cuda 0
|
||||
|
||||
The visdom dashboard shows memory as a heatmap for batch 0 every `-summarize_freq` iteration:
|
||||
|
||||
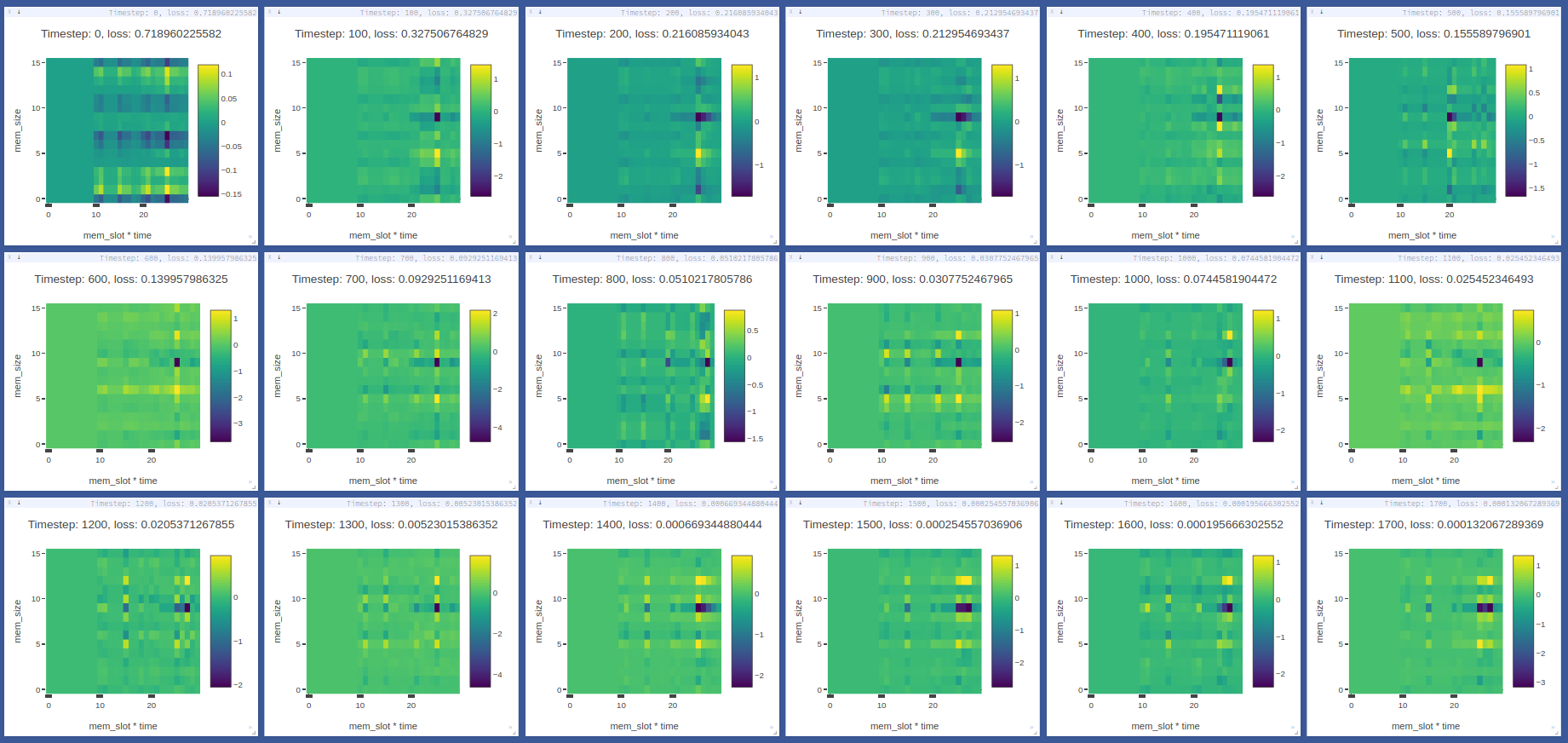
|
||||

|
||||
|
||||
|
||||
## General noteworthy stuff
|
||||
|
||||
1. DNCs converge with Adam and RMSProp learning rules, SGD generally causes them to diverge.
|
||||
2. Using a large batch size (> 100, recommended 1000) prevents gradients from becoming `NaN`.
|
||||
|
||||
Repos referred to for creation of this repo:
|
||||
|
||||
|
||||
204
dnc/dnc.py
204
dnc/dnc.py
@ -33,7 +33,8 @@ class DNC(nn.Module):
|
||||
gpu_id=-1,
|
||||
independent_linears=False,
|
||||
share_memory=True,
|
||||
debug=False
|
||||
debug=False,
|
||||
clip=20
|
||||
):
|
||||
super(DNC, self).__init__()
|
||||
# todo: separate weights and RNNs for the interface and output vectors
|
||||
@ -55,38 +56,32 @@ class DNC(nn.Module):
|
||||
self.independent_linears = independent_linears
|
||||
self.share_memory = share_memory
|
||||
self.debug = debug
|
||||
self.clip = clip
|
||||
|
||||
self.w = self.cell_size
|
||||
self.r = self.read_heads
|
||||
|
||||
# input size
|
||||
self.nn_input_size = self.r * self.w + self.input_size
|
||||
self.nn_output_size = self.r * self.w + self.hidden_size
|
||||
|
||||
self.interface_size = (self.w * self.r) + (3 * self.w) + (5 * self.r) + 3
|
||||
self.read_vectors_size = self.r * self.w
|
||||
self.interface_size = self.read_vectors_size + (3 * self.w) + (5 * self.r) + 3
|
||||
self.output_size = self.hidden_size
|
||||
|
||||
self.rnns = [[None] * self.num_hidden_layers] * self.num_layers
|
||||
self.nn_input_size = self.input_size + self.read_vectors_size
|
||||
self.nn_output_size = self.output_size + self.read_vectors_size
|
||||
|
||||
self.rnns = []
|
||||
self.memories = []
|
||||
|
||||
for layer in range(self.num_layers):
|
||||
# controllers for each layer
|
||||
for hlayer in range(self.num_hidden_layers):
|
||||
if self.rnn_type.lower() == 'rnn':
|
||||
if hlayer == 0:
|
||||
self.rnns[layer][hlayer] = nn.RNNCell(self.nn_input_size, self.output_size,bias=self.bias, nonlinearity=self.nonlinearity)
|
||||
else:
|
||||
self.rnns[layer][hlayer] = nn.RNNCell(self.output_size, self.output_size,bias=self.bias, nonlinearity=self.nonlinearity)
|
||||
elif self.rnn_type.lower() == 'gru':
|
||||
if hlayer == 0:
|
||||
self.rnns[layer][hlayer] = nn.GRUCell(self.nn_input_size, self.output_size, bias=self.bias)
|
||||
else:
|
||||
self.rnns[layer][hlayer] = nn.GRUCell(self.output_size, self.output_size, bias=self.bias)
|
||||
elif self.rnn_type.lower() == 'lstm':
|
||||
if hlayer == 0:
|
||||
self.rnns[layer][hlayer] = nn.LSTMCell(self.nn_input_size, self.output_size, bias=self.bias)
|
||||
else:
|
||||
self.rnns[layer][hlayer] = nn.LSTMCell(self.output_size, self.output_size, bias=self.bias)
|
||||
if self.rnn_type.lower() == 'rnn':
|
||||
self.rnns.append(nn.RNN((self.nn_input_size if layer == 0 else self.nn_output_size), self.output_size,
|
||||
bias=self.bias, nonlinearity=self.nonlinearity, batch_first=True, dropout=self.dropout))
|
||||
elif self.rnn_type.lower() == 'gru':
|
||||
self.rnns.append(nn.GRU((self.nn_input_size if layer == 0 else self.nn_output_size),
|
||||
self.output_size, bias=self.bias, batch_first=True, dropout=self.dropout))
|
||||
if self.rnn_type.lower() == 'lstm':
|
||||
self.rnns.append(nn.LSTM((self.nn_input_size if layer == 0 else self.nn_output_size),
|
||||
self.output_size, bias=self.bias, batch_first=True, dropout=self.dropout))
|
||||
setattr(self, self.rnn_type.lower() + '_layer_' + str(layer), self.rnns[layer])
|
||||
|
||||
# memories for each layer
|
||||
if not self.share_memory:
|
||||
@ -100,6 +95,7 @@ class DNC(nn.Module):
|
||||
independent_linears=self.independent_linears
|
||||
)
|
||||
)
|
||||
setattr(self, 'rnn_layer_memory_' + str(layer), self.memories[layer])
|
||||
|
||||
# only one memory shared by all layers
|
||||
if self.share_memory:
|
||||
@ -113,24 +109,14 @@ class DNC(nn.Module):
|
||||
independent_linears=self.independent_linears
|
||||
)
|
||||
)
|
||||
|
||||
for layer in range(self.num_layers):
|
||||
for hlayer in range(self.num_hidden_layers):
|
||||
setattr(self, 'rnn_layer_' + str(layer) + '_' + str(hlayer), self.rnns[layer][hlayer])
|
||||
if not self.share_memory:
|
||||
setattr(self, 'rnn_layer_memory_' + str(layer), self.memories[layer])
|
||||
if self.share_memory:
|
||||
setattr(self, 'rnn_layer_memory_shared', self.memories[0])
|
||||
|
||||
# final output layer
|
||||
self.output_weights = nn.Linear(self.output_size, self.output_size)
|
||||
self.mem_out = nn.Linear(self.nn_output_size, self.input_size)
|
||||
self.dropout_layer = nn.Dropout(self.dropout)
|
||||
self.output = nn.Linear(self.nn_output_size, self.input_size)
|
||||
|
||||
if self.gpu_id != -1:
|
||||
[x.cuda(self.gpu_id) for y in self.rnns for x in y]
|
||||
[x.cuda(self.gpu_id) for x in self.rnns]
|
||||
[x.cuda(self.gpu_id) for x in self.memories]
|
||||
self.mem_out.cuda(self.gpu_id)
|
||||
|
||||
def _init_hidden(self, hx, batch_size, reset_experience):
|
||||
# create empty hidden states if not provided
|
||||
@ -140,11 +126,7 @@ class DNC(nn.Module):
|
||||
|
||||
# initialize hidden state of the controller RNN
|
||||
if chx is None:
|
||||
chx = cuda(T.zeros(batch_size, self.output_size), gpu_id=self.gpu_id)
|
||||
if self.rnn_type.lower() == 'lstm':
|
||||
chx = [ [ (chx.clone(), chx.clone()) for h in range(self.num_hidden_layers) ] for l in range(self.num_layers) ]
|
||||
else:
|
||||
chx = [ [ chx.clone() for h in range(self.num_hidden_layers) ] for l in range(self.num_layers) ]
|
||||
chx = [None for x in range(self.num_layers)]
|
||||
|
||||
# Last read vectors
|
||||
if last_read is None:
|
||||
@ -164,41 +146,54 @@ class DNC(nn.Module):
|
||||
|
||||
return chx, mhx, last_read
|
||||
|
||||
def _layer_forward(self, input, layer, hx=(None, None)):
|
||||
def _debug(self, mhx, debug_obj):
|
||||
if not debug_obj:
|
||||
debug_obj = {
|
||||
'memory': [],
|
||||
'link_matrix': [],
|
||||
'precedence': [],
|
||||
'read_weights': [],
|
||||
'write_weights': [],
|
||||
'usage_vector': [],
|
||||
}
|
||||
|
||||
debug_obj['memory'].append(mhx['memory'][0].data.cpu().numpy())
|
||||
debug_obj['link_matrix'].append(mhx['link_matrix'][0][0].data.cpu().numpy())
|
||||
debug_obj['precedence'].append(mhx['precedence'][0].data.cpu().numpy())
|
||||
debug_obj['read_weights'].append(mhx['read_weights'][0].data.cpu().numpy())
|
||||
debug_obj['write_weights'].append(mhx['write_weights'][0].data.cpu().numpy())
|
||||
debug_obj['usage_vector'].append(mhx['usage_vector'][0].unsqueeze(0).data.cpu().numpy())
|
||||
return debug_obj
|
||||
|
||||
def _layer_forward(self, input, layer, hx=(None, None), pass_through_memory=True):
|
||||
(chx, mhx) = hx
|
||||
max_length = len(input)
|
||||
outs = [0] * max_length
|
||||
read_vectors = [0] * max_length
|
||||
|
||||
for time in range(max_length):
|
||||
# pass through controller
|
||||
layer_input = input[time]
|
||||
hchx = []
|
||||
# pass through the controller layer
|
||||
input, chx = self.rnns[layer](input.unsqueeze(1), chx)
|
||||
input = input.squeeze(1)
|
||||
|
||||
for hlayer in range(self.num_hidden_layers):
|
||||
h = self.rnns[layer][hlayer](layer_input, chx[hlayer])
|
||||
layer_input = h[0] if self.rnn_type.lower() == 'lstm' else h
|
||||
hchx.append(h)
|
||||
chx = hchx
|
||||
# the interface vector
|
||||
ξ = input
|
||||
# clip the controller output
|
||||
if self.clip != 0:
|
||||
output = T.clamp(input, -self.clip, self.clip)
|
||||
else:
|
||||
output = input
|
||||
|
||||
# the interface vector
|
||||
ξ = layer_input
|
||||
# the output
|
||||
out = self.output_weights(layer_input)
|
||||
|
||||
# pass through memory
|
||||
# pass through memory
|
||||
if pass_through_memory:
|
||||
if self.share_memory:
|
||||
read_vecs, mhx = self.memories[0](ξ, mhx)
|
||||
else:
|
||||
read_vecs, mhx = self.memories[layer](ξ, mhx)
|
||||
read_vectors[time] = read_vecs.view(-1, self.w * self.r)
|
||||
# the read vectors
|
||||
read_vectors = read_vecs.view(-1, self.w * self.r)
|
||||
else:
|
||||
read_vectors = None
|
||||
|
||||
# get the final output for this time step
|
||||
outs[time] = self.dropout_layer(self.mem_out(T.cat([out, read_vectors[time]], 1)))
|
||||
return output, read_vectors, (chx, mhx)
|
||||
|
||||
return outs, read_vectors, (chx, mhx)
|
||||
|
||||
def forward(self, input, hx=(None, None, None), reset_experience=False):
|
||||
def forward(self, input, hx=(None, None, None), reset_experience=False, pass_through_memory=True):
|
||||
# handle packed data
|
||||
is_packed = type(input) is PackedSequence
|
||||
if is_packed:
|
||||
@ -210,64 +205,61 @@ class DNC(nn.Module):
|
||||
|
||||
batch_size = input.size(0) if self.batch_first else input.size(1)
|
||||
|
||||
# make the data batch-first
|
||||
if not self.batch_first:
|
||||
input = input.transpose(0, 1)
|
||||
# make the data time-first
|
||||
|
||||
controller_hidden, mem_hidden, last_read = self._init_hidden(hx, batch_size, reset_experience)
|
||||
|
||||
# concat input with last read (or padding) vectors
|
||||
inputs = [T.cat([input[:, x, :], last_read], 1) for x in range(max_length)]
|
||||
|
||||
# batched forward pass per element / word / etc
|
||||
outputs = None
|
||||
chxs = []
|
||||
if self.debug:
|
||||
viz = [mem_hidden['memory'][0]] if self.share_memory else [mem_hidden[0]['memory'][0]]
|
||||
viz = None
|
||||
|
||||
read_vectors = [last_read] * max_length
|
||||
# outs = [input[:, x, :] for x in range(max_length)]
|
||||
outs = [T.cat([input[:, x, :], last_read], 1) for x in range(max_length)]
|
||||
outs = [None] * max_length
|
||||
read_vectors = None
|
||||
|
||||
for layer in range(self.num_layers):
|
||||
# this layer's hidden states
|
||||
chx = controller_hidden[layer]
|
||||
# pass through time
|
||||
for time in range(max_length):
|
||||
# pass thorugh layers
|
||||
for layer in range(self.num_layers):
|
||||
# this layer's hidden states
|
||||
chx = controller_hidden[layer]
|
||||
m = mem_hidden if self.share_memory else mem_hidden[layer]
|
||||
# pass through controller
|
||||
outs[time], read_vectors, (chx, m) = \
|
||||
self._layer_forward(inputs[time], layer, (chx, m), pass_through_memory)
|
||||
|
||||
m = mem_hidden if self.share_memory else mem_hidden[layer]
|
||||
# pass through controller
|
||||
outs, _, (chx, m) = self._layer_forward(
|
||||
outs,
|
||||
layer,
|
||||
(chx, m)
|
||||
)
|
||||
# debug memory
|
||||
if self.debug:
|
||||
viz = self._debug(m, viz)
|
||||
|
||||
# debug memory
|
||||
if self.debug:
|
||||
viz.append(m['memory'][0])
|
||||
# store the memory back (per layer or shared)
|
||||
if self.share_memory:
|
||||
mem_hidden = m
|
||||
else:
|
||||
mem_hidden[layer] = m
|
||||
controller_hidden[layer] = chx
|
||||
|
||||
# store the memory back (per layer or shared)
|
||||
if self.share_memory:
|
||||
mem_hidden = m
|
||||
else:
|
||||
mem_hidden[layer] = m
|
||||
chxs.append(chx)
|
||||
|
||||
if layer == self.num_layers - 1:
|
||||
# final outputs
|
||||
outputs = T.stack(outs, 1)
|
||||
else:
|
||||
# the controller output + read vectors go into next layer
|
||||
outs = [T.cat([o, r], 1) for o, r in zip(outs, read_vectors)]
|
||||
# outs = [o for o in outs]
|
||||
if read_vectors is not None:
|
||||
# the controller output + read vectors go into next layer
|
||||
outs[time] = T.cat([outs[time], read_vectors], 1)
|
||||
inputs[time] = outs[time]
|
||||
|
||||
if self.debug:
|
||||
viz = T.cat(viz, 0).transpose(0, 1)
|
||||
viz = {k: np.array(v) for k, v in viz.items()}
|
||||
viz = {k: v.reshape(v.shape[0], v.shape[1] * v.shape[2]) for k, v in viz.items()}
|
||||
|
||||
controller_hidden = chxs
|
||||
# pass through final output layer
|
||||
inputs = [self.output(i) for i in inputs]
|
||||
outputs = T.stack(inputs, 1 if self.batch_first else 0)
|
||||
|
||||
if not self.batch_first:
|
||||
outputs = outputs.transpose(0, 1)
|
||||
if is_packed:
|
||||
outputs = pack(output, lengths)
|
||||
|
||||
if self.debug:
|
||||
return outputs, (controller_hidden, mem_hidden, read_vectors[-1]), viz
|
||||
return outputs, (controller_hidden, mem_hidden, read_vectors), viz
|
||||
else:
|
||||
return outputs, (controller_hidden, mem_hidden, read_vectors[-1])
|
||||
return outputs, (controller_hidden, mem_hidden, read_vectors)
|
||||
|
||||
@ -87,24 +87,18 @@ class Memory(nn.Module):
|
||||
# free list
|
||||
sorted_usage, φ = T.topk(usage, self.mem_size, dim=1, largest=False)
|
||||
|
||||
# cumprod with exclusive=True, TODO: unstable territory, revisit this shit
|
||||
# essential for correct scaling of allocation_weights to prevent memory pollution
|
||||
# during write operations
|
||||
# cumprod with exclusive=True
|
||||
# https://discuss.pytorch.org/t/cumprod-exclusive-true-equivalences/2614/8
|
||||
v = var(T.ones(batch_size, 1))
|
||||
if self.gpu_id != -1:
|
||||
v = v.cuda(self.gpu_id)
|
||||
cat_sorted_usage = T.cat((v, sorted_usage), 1)[:, :-1]
|
||||
prod_sorted_usage = fake_cumprod(cat_sorted_usage, self.gpu_id)
|
||||
v = var(sorted_usage.data.new(batch_size, 1).fill_(1))
|
||||
cat_sorted_usage = T.cat((v, sorted_usage), 1)
|
||||
prod_sorted_usage = T.cumprod(cat_sorted_usage, 1)[:, :-1]
|
||||
|
||||
sorted_allocation_weights = (1 - sorted_usage) * prod_sorted_usage.squeeze()
|
||||
|
||||
# construct the reverse sorting index https://stackoverflow.com/questions/2483696/undo-or-reverse-argsort-python
|
||||
_, φ_rev = T.topk(φ, k=self.mem_size, dim=1, largest=False)
|
||||
allocation_weights = sorted_allocation_weights.gather(1, φ.long())
|
||||
allocation_weights = sorted_allocation_weights.gather(1, φ_rev.long())
|
||||
|
||||
# update usage after allocating
|
||||
# usage += ((1 - usage) * write_gate * allocation_weights)
|
||||
return allocation_weights.unsqueeze(1), usage
|
||||
|
||||
def write_weighting(self, memory, write_content_weights, allocation_weights, write_gate, allocation_gate):
|
||||
@ -145,6 +139,7 @@ class Memory(nn.Module):
|
||||
hidden['usage_vector'],
|
||||
allocation_gate * write_gate
|
||||
)
|
||||
# print((alloc).data.cpu().numpy())
|
||||
|
||||
# get write weightings
|
||||
hidden['write_weights'] = self.write_weighting(
|
||||
@ -244,11 +239,11 @@ class Memory(nn.Module):
|
||||
# r read keys (b * w * r)
|
||||
read_keys = ξ[:, :r * w].contiguous().view(b, r, w)
|
||||
# r read strengths (b * r)
|
||||
read_strengths = 1 + F.relu(ξ[:, r * w:r * w + r].contiguous().view(b, r))
|
||||
read_strengths = ξ[:, r * w:r * w + r].contiguous().view(b, r)
|
||||
# write key (b * w * 1)
|
||||
write_key = ξ[:, r * w + r:r * w + r + w].contiguous().view(b, 1, w)
|
||||
# write strength (b * 1)
|
||||
write_strength = 1 + F.relu(ξ[:, r * w + r + w].contiguous()).view(b, 1)
|
||||
write_strength = ξ[:, r * w + r + w].contiguous().view(b, 1)
|
||||
# erase vector (b * w)
|
||||
erase_vector = F.sigmoid(ξ[:, r * w + r + w + 1: r * w + r + 2 * w + 1].contiguous().view(b, 1, w))
|
||||
# write vector (b * w)
|
||||
|
||||
23
dnc/util.py
23
dnc/util.py
@ -43,29 +43,6 @@ def cudalong(x, grad=False, gpu_id=-1):
|
||||
return var(T.from_numpy(x.astype(np.long)).pin_memory(), requires_grad=grad).cuda(gpu_id, async=True)
|
||||
|
||||
|
||||
def fake_cumprod(vb, gpu_id):
|
||||
"""
|
||||
args:
|
||||
vb: [hei x wid]
|
||||
-> NOTE: we are lazy here so now it only supports cumprod along wid
|
||||
"""
|
||||
# real_cumprod = torch.cumprod(vb.data, 1)
|
||||
vb = vb.unsqueeze(0)
|
||||
mul_mask_vb = Variable(torch.zeros(vb.size(2), vb.size(1), vb.size(2))).type_as(vb)
|
||||
|
||||
if gpu_id != -1:
|
||||
mul_mask_vb = mul_mask_vb.cuda(gpu_id)
|
||||
|
||||
for i in range(vb.size(2)):
|
||||
mul_mask_vb[i, :, :i + 1] = 1
|
||||
add_mask_vb = 1 - mul_mask_vb
|
||||
vb = vb.expand_as(mul_mask_vb) * mul_mask_vb + add_mask_vb
|
||||
# vb = torch.prod(vb, 2).transpose(0, 2) # 0.1.12
|
||||
vb = torch.prod(vb, 2, keepdim=True).transpose(0, 2) # 0.2.0
|
||||
# print(real_cumprod - vb.data) # NOTE: checked, ==0
|
||||
return vb
|
||||
|
||||
|
||||
def θ(a, b, dimA=2, dimB=2, normBy=2):
|
||||
"""Batchwise Cosine distance
|
||||
|
||||
|
||||
BIN
docs/dnc-mem-debug.png
Normal file
BIN
docs/dnc-mem-debug.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 169 KiB |
@ -29,10 +29,11 @@ parser.add_argument('-rnn_type', type=str, default='lstm', help='type of recurre
|
||||
parser.add_argument('-nhid', type=int, default=64, help='number of hidden units of the inner nn')
|
||||
parser.add_argument('-dropout', type=float, default=0, help='controller dropout')
|
||||
|
||||
parser.add_argument('-nlayer', type=int, default=2, help='number of layers')
|
||||
parser.add_argument('-nlayer', type=int, default=1, help='number of layers')
|
||||
parser.add_argument('-nhlayer', type=int, default=2, help='number of hidden layers')
|
||||
parser.add_argument('-lr', type=float, default=1e-2, help='initial learning rate')
|
||||
parser.add_argument('-clip', type=float, default=0.5, help='gradient clipping')
|
||||
parser.add_argument('-lr', type=float, default=1e-4, help='initial learning rate')
|
||||
parser.add_argument('-optim', type=str, default='adam', help='learning rule, supports adam|rmsprop')
|
||||
parser.add_argument('-clip', type=float, default=50, help='gradient clipping')
|
||||
|
||||
parser.add_argument('-batch_size', type=int, default=100, metavar='N', help='batch size')
|
||||
parser.add_argument('-mem_size', type=int, default=16, help='memory dimension')
|
||||
@ -119,7 +120,8 @@ if __name__ == '__main__':
|
||||
cell_size=mem_size,
|
||||
read_heads=read_heads,
|
||||
gpu_id=args.cuda,
|
||||
debug=True
|
||||
debug=True,
|
||||
batch_first=True
|
||||
)
|
||||
print(rnn)
|
||||
|
||||
@ -128,7 +130,10 @@ if __name__ == '__main__':
|
||||
|
||||
last_save_losses = []
|
||||
|
||||
optimizer = optim.Adam(rnn.parameters(), lr=args.lr)
|
||||
if args.optim == 'adam':
|
||||
optimizer = optim.Adam(rnn.parameters(), lr=args.lr, eps=1e-9, betas=[0.9, 0.98])
|
||||
elif args.optim == 'rmsprop':
|
||||
optimizer = optim.RMSprop(rnn.parameters(), lr=args.lr, eps=1e-10)
|
||||
|
||||
for epoch in range(iterations + 1):
|
||||
llprint("\rIteration {ep}/{tot}".format(ep=epoch, tot=iterations))
|
||||
@ -137,18 +142,14 @@ if __name__ == '__main__':
|
||||
random_length = np.random.randint(1, sequence_max_length + 1)
|
||||
|
||||
input_data, target_output = generate_data(batch_size, random_length, args.input_size, args.cuda)
|
||||
# input_data = input_data.transpose(0, 1).contiguous()
|
||||
target_output = target_output.transpose(0, 1).contiguous()
|
||||
|
||||
output, (chx, mhx, rv), v = rnn(input_data, None)
|
||||
|
||||
output = output.transpose(0, 1)
|
||||
if rnn.debug:
|
||||
output, (chx, mhx, rv), v = rnn(input_data, None, pass_through_memory=True)
|
||||
else:
|
||||
output, (chx, mhx, rv) = rnn(input_data, None, pass_through_memory=True)
|
||||
|
||||
loss = criterion((output), target_output)
|
||||
# if np.isnan(loss.data.cpu().numpy()):
|
||||
# llprint('\nGot nan loss, contine to jump the backward \n')
|
||||
|
||||
# apply_dict(locals())
|
||||
loss.backward()
|
||||
|
||||
T.nn.utils.clip_grad_norm(rnn.parameters(), args.clip)
|
||||
@ -160,19 +161,79 @@ if __name__ == '__main__':
|
||||
|
||||
last_save_losses.append(loss_value)
|
||||
|
||||
if summarize:
|
||||
if summarize and rnn.debug:
|
||||
loss = np.mean(last_save_losses)
|
||||
# print(input_data)
|
||||
# print("1111111111111111111111111111111111111111111111")
|
||||
# print(target_output)
|
||||
# print('2222222222222222222222222222222222222222222222')
|
||||
# print(F.relu6(output))
|
||||
llprint("\n\tAvg. Logistic Loss: %.4f\n" % (loss))
|
||||
last_save_losses = []
|
||||
|
||||
viz.heatmap(
|
||||
v.data.cpu().numpy(),
|
||||
v['memory'],
|
||||
opts=dict(
|
||||
xtickstep=10,
|
||||
ytickstep=2,
|
||||
title='Timestep: ' + str(epoch) + ', loss: ' + str(loss),
|
||||
xlabel='mem_slot * layer',
|
||||
ylabel='mem_size'
|
||||
title='Memory, t: ' + str(epoch) + ', loss: ' + str(loss),
|
||||
ylabel='layer * time',
|
||||
xlabel='mem_slot * mem_size'
|
||||
)
|
||||
)
|
||||
|
||||
viz.heatmap(
|
||||
v['link_matrix'],
|
||||
opts=dict(
|
||||
xtickstep=10,
|
||||
ytickstep=2,
|
||||
title='Link Matrix, t: ' + str(epoch) + ', loss: ' + str(loss),
|
||||
ylabel='layer * time',
|
||||
xlabel='mem_slot * mem_slot'
|
||||
)
|
||||
)
|
||||
|
||||
viz.heatmap(
|
||||
v['precedence'],
|
||||
opts=dict(
|
||||
xtickstep=10,
|
||||
ytickstep=2,
|
||||
title='Precedence, t: ' + str(epoch) + ', loss: ' + str(loss),
|
||||
ylabel='layer * time',
|
||||
xlabel='mem_slot'
|
||||
)
|
||||
)
|
||||
|
||||
viz.heatmap(
|
||||
v['read_weights'],
|
||||
opts=dict(
|
||||
xtickstep=10,
|
||||
ytickstep=2,
|
||||
title='Read Weights, t: ' + str(epoch) + ', loss: ' + str(loss),
|
||||
ylabel='layer * time',
|
||||
xlabel='nr_read_heads * mem_slot'
|
||||
)
|
||||
)
|
||||
|
||||
viz.heatmap(
|
||||
v['write_weights'],
|
||||
opts=dict(
|
||||
xtickstep=10,
|
||||
ytickstep=2,
|
||||
title='Write Weights, t: ' + str(epoch) + ', loss: ' + str(loss),
|
||||
ylabel='layer * time',
|
||||
xlabel='mem_slot'
|
||||
)
|
||||
)
|
||||
|
||||
viz.heatmap(
|
||||
v['usage_vector'],
|
||||
opts=dict(
|
||||
xtickstep=10,
|
||||
ytickstep=2,
|
||||
title='Usage Vector, t: ' + str(epoch) + ', loss: ' + str(loss),
|
||||
ylabel='layer * time',
|
||||
xlabel='mem_slot'
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@ -74,7 +74,7 @@ def test_rnn_1():
|
||||
assert target_output.size() == T.Size([21, 10, 100])
|
||||
assert chx[0][0].size() == T.Size([10,100])
|
||||
assert mhx['memory'].size() == T.Size([10,1,1])
|
||||
assert rv.size() == T.Size([10,1])
|
||||
assert rv.size() == T.Size([10, 1])
|
||||
|
||||
|
||||
def test_rnn_n():
|
||||
@ -128,6 +128,6 @@ def test_rnn_n():
|
||||
optimizer.step()
|
||||
|
||||
assert target_output.size() == T.Size([27, 10, 100])
|
||||
assert chx[1][2].size() == T.Size([10,100])
|
||||
assert chx[1].size() == T.Size([1,10,100])
|
||||
assert mhx['memory'].size() == T.Size([10,12,17])
|
||||
assert rv.size() == T.Size([10,51])
|
||||
assert rv.size() == T.Size([10, 51])
|
||||
|
||||
@ -74,7 +74,7 @@ def test_rnn_1():
|
||||
assert target_output.size() == T.Size([21, 10, 100])
|
||||
assert chx[0][0][0].size() == T.Size([10,100])
|
||||
assert mhx['memory'].size() == T.Size([10,1,1])
|
||||
assert rv.size() == T.Size([10,1])
|
||||
assert rv.size() == T.Size([10, 1])
|
||||
|
||||
|
||||
def test_rnn_n():
|
||||
@ -128,6 +128,6 @@ def test_rnn_n():
|
||||
optimizer.step()
|
||||
|
||||
assert target_output.size() == T.Size([27, 10, 100])
|
||||
assert chx[0][0][0].size() == T.Size([10,100])
|
||||
assert chx[0][0].size() == T.Size([1,10,100])
|
||||
assert mhx['memory'].size() == T.Size([10,12,17])
|
||||
assert rv.size() == T.Size([10,51])
|
||||
assert rv.size() == T.Size([10, 51])
|
||||
|
||||
@ -74,7 +74,7 @@ def test_rnn_1():
|
||||
assert target_output.size() == T.Size([21, 10, 100])
|
||||
assert chx[0][0].size() == T.Size([10,100])
|
||||
assert mhx['memory'].size() == T.Size([10,1,1])
|
||||
assert rv.size() == T.Size([10,1])
|
||||
assert rv.size() == T.Size([10, 1])
|
||||
|
||||
|
||||
def test_rnn_n():
|
||||
@ -128,6 +128,6 @@ def test_rnn_n():
|
||||
optimizer.step()
|
||||
|
||||
assert target_output.size() == T.Size([27, 10, 100])
|
||||
assert chx[1][2].size() == T.Size([10,100])
|
||||
assert chx[1].size() == T.Size([1,10,100])
|
||||
assert mhx['memory'].size() == T.Size([10,12,17])
|
||||
assert rv.size() == T.Size([10,51])
|
||||
assert rv.size() == T.Size([10, 51])
|
||||
|
||||
Loading…
Reference in New Issue
Block a user