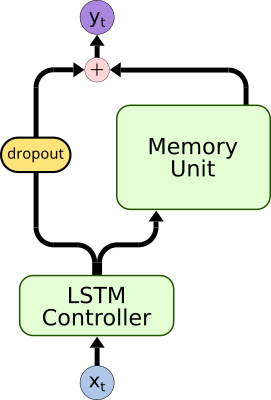
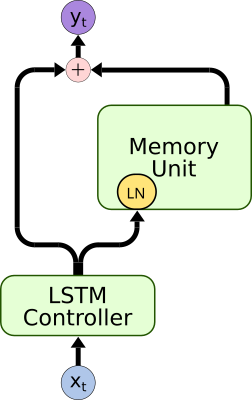

- Dropout to reduce the bypass connectivity
- Forces an earlier memory usage during training
- Normalizes the memory unit's input
- Increases the model stability during training
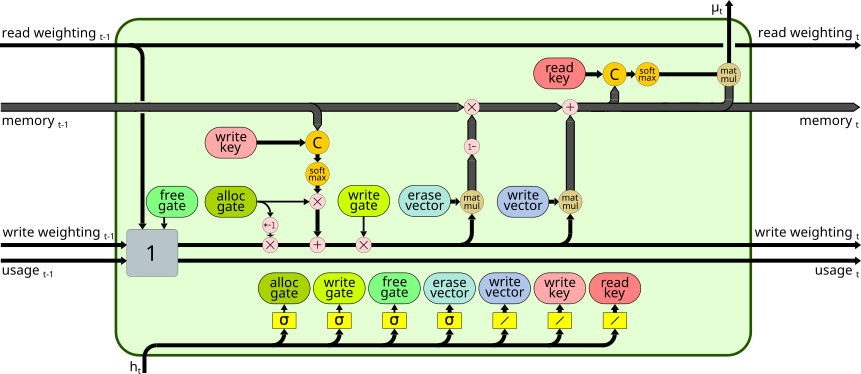
- Memory Unit without temporal linkage mechanism
- Reduces memory consumption by up to 70
- Bidirectional DNC Architecture
- Allows to handle variable requests and rich information extraction