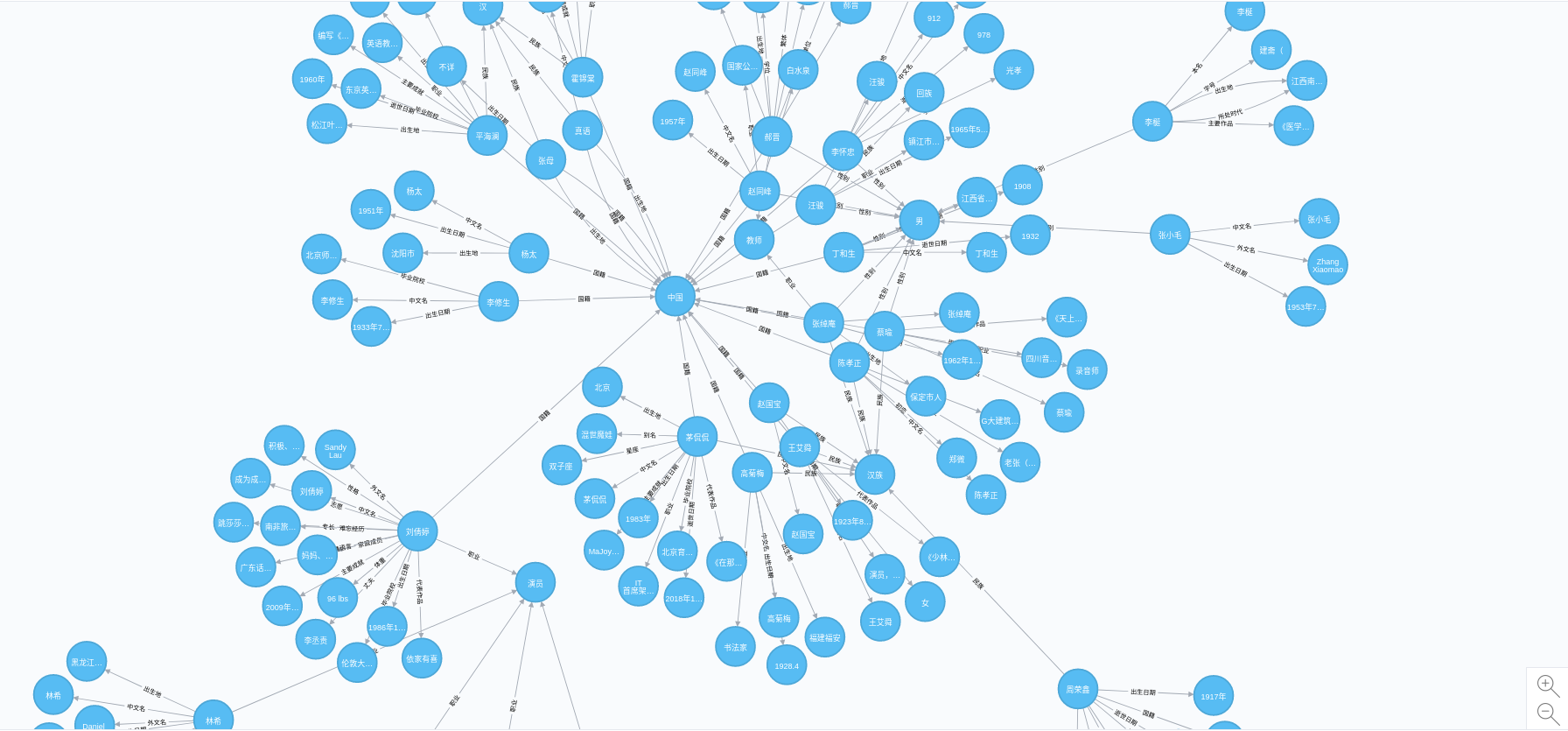
爬取百度百科中文页面,抽取三元组信息,构建中文知识图谱
| ie | ||
| info | ||
| kg | ||
| spider | ||
| .gitignore | ||
| dict.txt | ||
| output.txt | ||
| README.md | ||
开源web知识图谱项目
- 爬取百度百科中文页面
- 抽取100W+个三元组
- 构建中文知识图谱
环境
- python 3.6
- requests:网络请求
- re:url正则匹配
- bs4:网页解析
- pickle:进度保存
- threading:多线程
- neo4j:知识图谱图数据库,安装可以参考链接
- pip install neo4j-driver:neo4j python驱动
运行前指定几个路径:
spider/html_paser.py第38行为网页存储路径:
path='/data/ruben/data/webpages/'#custom diectory for webpages
ie/extract-para.py第11行为网页存储路径:
pages=glob.glob('/data/ruben/data/webpages/*')
ie/extract-table.py第37行为网页存储路径:
pages=glob.glob('/data/ruben/data/webpages/*')
代码目錄
- spider/ 抓取原始网页
- ie/ 从网页中解析正文,从正文中抽取结构化信息
- kg/ 抽取三元組,存入neo4j数据库
代码执行顺序:
python spider/spider_main.py
python ie/extract-para.py
python ie/extract-table.py
python kg/test_neo4j.py